

TL;DR
Llama 3 초기 버전 출시 후 예고되었던 405B 모델이 출시되었다. 이런 저런 업데이트를 포함하여, Llama 3.1로 발표가 되었다. 405B 모델의 성능은 공개 모델만큼 강력해보이지만, 높은 인프라 수준을 요구할 것으로 보인다.
이 외에도 각종 개발 편의성이나 안정성이 개선된 것으로 보인다. 모델을 사용해보기 전에, 먼저 공식 홈페이지의 릴리즈 노트를 살펴보자.
* 가독성을 위해 그림 크기를 최소화했습니다. 클릭 시 확대됩니다.
출처: https://ai.meta.com/blog/meta-llama-3-1/
Introducing Llama 3.1: Our most capable models to date
For this release, we evaluated performance on over 150 benchmark datasets that span a wide range of languages. In addition, we performed extensive human evaluations that compare Llama 3.1 with competing models in real-world scenarios. Our experimental eval
ai.meta.com
Introducing Llama 3.1: Our most capable models to date
Llama 3.1 소개: Meta의 가장 유능한 모델
주요 내용:
- Meta는 오픈 소스 AI에 대한 헌신을 표명함. Mark Zuckerberg의 편지에서 오픈 소스가 개발자, Meta, 그리고 세계에 왜 좋은지 설명함(참고: Zuckerberg의 인스타그램 영상).
https://www.instagram.com/zuck/reel/C9xOz1gPKcy
Instagram의 Mark Zuckerberg님 : "Meta AI is en fuego and Llama 3.1 is a banger! 💪"
146K likes, 7,930 comments - zuck - July 23, 2024: "Meta AI is en fuego and Llama 3.1 is a banger! 💪".
www.instagram.com
- Llama의 최신 모델은 컨텍스트 길이를 128K로 확장하고, 8개 언어를 지원하며, 첫 번째 최전선 오픈 소스 AI 모델인 Llama 3.1 405B를 포함함.
- Llama 3.1 405B는 유연성, 제어력, 최첨단 기능에서 독보적이며, 최고의 폐쇄 소스 모델과 견줄만한 성능을 보임. 커뮤니티는 이를 통해 합성 데이터 생성, 모델 증류 등의 새로운 워크플로우를 열 수 있음.
- Llama를 시스템으로 구축하기 위해 모델과 함께 작동하는 더 많은 구성 요소, 참조 시스템(reference system) 제공. 개발자가 맞춤형 에이전트와 새로운 유형의 에이전트 행동을 만들 수 있도록 도구를 제공.
- 새로운 보안 및 안전 도구 Llama Guard 3와 Prompt Guard를 통해 개발자가 책임감 있게 빌드할 수 있도록 지원.
- 또한 Llama Stack API에 대한 요청 의견을 공개하여 서드파티 프로젝트가 Llama 모델을 쉽게 활용할 수 있도록 표준 인터페이스를 제공하고자 함.
- 25개 이상의 파트너사(AWS, NVIDIA, Databricks, Groq, Dell, Azure, Google Cloud, Snowflake 포함)가 첫날부터 서비스를 제공할 준비가 되어 있음.
- Llama 3.1 405B를 미국 내 WhatsApp 및 meta.ai에서 사용해보고 어려운 수학 또는 코딩 질문을 물어볼 수 있음.
Llama 3.1 소개
- Llama 3.1 405B는 일반 지식, 유도 가능성, 수학, 도구 사용, 다국어 번역에서 최첨단 기능을 갖춘 최초의 공개 가능 모델임.
- 405B 모델의 출시로 혁신을 가속화할 수 있는 전례 없는 기회 제공. 최신 Llama 세대는 합성 데이터 생성 및 모델 증류와 같은 새로운 애플리케이션과 모델링 패러다임을 촉발할 것으로 기대됨. 이는 소규모 모델의 개선 및 훈련을 가능하게 함.
- 업그레이드된 8B 및 70B 모델도 함께 출시됨. 이 모델들은 다국어 지원, 128K의 긴 컨텍스트 길이, 최첨단 도구 사용, 강력한 추론 능력을 갖춤. 이를 통해 장문 텍스트 요약, 다국어 대화 에이전트, 코딩 어시스턴트와 같은 고급 사용 사례를 지원할 수 있음.
- 라이선스를 변경하여 개발자가 Llama 모델의 출력물을 사용해 다른 모델을 개선할 수 있도록 함.
- 오늘부터 Llama 모델을 llama.meta.com 및 HuggingFace 커뮤니티에 공개하여 다운로드 가능. 파트너 플랫폼의 광범위한 생태계에서 즉시 개발 가능.
모델 평가
- 이번 출시를 위해 150개 이상의 벤치마크 데이터셋을 사용해 다양한 언어에 대한 성능 평가를 수행함.
- Llama 3.1을 경쟁 모델과 비교한 광범위한 인간 평가도 실시함.
- 실험 평가 결과, 주요 모델이 GPT-4, GPT-4o, Claude 3.5 Sonnet과 같은 다양한 작업에서 선도적인 기초 모델과 경쟁할 수 있음을 확인함.
- 또한, 소형 모델도 유사한 파라미터 수를 가진 폐쇄 및 오픈 모델과 경쟁할 수 있음.
[그림은 클릭하면 확대됩니다]



모델 구조
- Llama 3.1 405B는 15조 개 이상의 토큰을 학습시킨 가장 큰 모델로, 이를 가능하게 하기 위해 16,000개 이상의 H100 GPU를 활용하여 모델을 훈련함. 이는 Llama 모델 중 처음으로 이러한 규모에서 훈련된 모델임.
- 모델 설계 선택:
- 안정적인 훈련을 위해 혼합 전문가(Mixture-of-Experts, MoE) 모델 대신 표준 디코더 전용 트랜스포머 모델 아키텍처를 약간 수정하여 사용함.
- 각 라운드마다 감독된 미세 조정 및 직접 선호 최적화를 사용하는 반복 후 훈련 절차를 채택함. 이를 통해 각 라운드에서 최고 품질의 합성 데이터를 생성하고 각 기능의 성능을 향상시킴.
- 데이터 개선:
- 이전 Llama 버전과 비교해 사전 및 후 훈련에 사용된 데이터의 양과 질을 개선함.
- 사전 훈련 데이터의 전처리 및 큐레이션 파이프라인을 더 신중하게 개발하고, 후 훈련 데이터에 대한 엄격한 품질 보증 및 필터링 접근 방식을 도입함.
- 스케일링 법칙에 따라, 새로운 주요 모델은 동일한 절차를 사용하여 훈련된 소형 모델보다 더 우수한 성능을 보임.
- 양자화:
- 405B 모델의 대규모 생산 추론을 지원하기 위해 16비트(BF16)에서 8비트(FP8) 숫자로 모델을 양자화하여 필요한 연산 요구 사항을 효과적으로 줄이고, 단일 서버 노드 내에서 모델을 실행할 수 있게 함.

지시 및 대화에 대한 미세 조정(Fine-tuning)
- Llama 3.1 405B는 사용자 지시에 대한 도움의 질과 세부 지시를 따르는 능력을 향상시키고, 높은 수준의 안전성을 유지하도록 설계됨.
- 주요 도전 과제는 더 많은 기능 지원, 128K 컨텍스트 윈도우, 증가된 모델 크기였음.
- Post-training 과정:
- 사전 훈련된 모델 위에 여러 라운드의 정렬 과정을 통해 최종 채팅 모델을 생성함.
- 각 라운드는 Fine-Tuning (SFT), Rejection Sampling (RS), Direct Preference Optimization
(DPO)를 포함함. - 대부분의 SFT 예제는 합성 데이터 생성을 통해 생산하며, 여러 번 반복하여 모든 기능에서 더 높은 품질의 합성 데이터를 생산함.
- 여러 데이터 처리 기법을 사용해 이 합성 데이터를 필터링하여 최고 품질을 유지함으로써 기능 전반에 걸쳐 미세 조정 데이터의 양을 확장할 수 있게 함.
- 데이터 균형:
- 모든 기능에서 높은 품질의 모델을 생산하기 위해 신중하게 데이터의 균형을 맞춤.
- 예를 들어, 128K 컨텍스트로 확장하면서도 짧은 컨텍스트 벤치마크에서 모델의 품질을 유지함.
- 안전 조치를 추가하면서도 최대한 도움이 되는 답변을 계속 제공할 수 있도록 함.
Llama 시스템
- Llama 모델은 외부 도구 호출을 포함한 여러 구성 요소를 조율하는 전체 시스템의 일부로 작동하도록 설계됨.
- 개발자가 자신의 비전에 맞는 맞춤형 제품을 설계하고 제작할 수 있는 유연성을 제공하기 위해 기본 모델을 넘어서는 시스템 접근을 목표로 함. 이러한 접근 방식은 작년 처음으로 LLM 외부 구성 요소의 통합을 도입하면서 시작됨.
- 책임감 있는 AI 개발 노력:
- 모델 레이어를 넘어 AI를 책임감 있게 개발하고 다른 사람들이 동일한 일을 할 수 있도록 돕기 위해 여러 샘플 애플리케이션과 새로운 구성 요소를 포함한 참조 시스템을 공개함.
- Llama Guard 3(다국어 안전 모델)와 Prompt Guard(프롬프트 주입 필터)와 같은 구성 요소를 포함하며, 이러한 샘플 애플리케이션은 오픈 소스로 커뮤니티에서 확장 가능함.
- 구성 요소 구현:
- Llama 시스템 비전의 구성 요소 구현은 아직 분산되어 있음.
- 이를 해결하기 위해 산업, 스타트업, 커뮤니티와 협력하여 구성 요소 인터페이스를 더 잘 정의하기 위해 노력 중임.
- 이를 지원하기 위해 GitHub에 "Llama Stack"이라는 표준화된 인터페이스 세트에 대한 의견 요청을 발표함. Llama Stack은 정형화된 도구 체인 구성 요소(미세 조정, 합성 데이터 생성) 및 에이전트 애플리케이션을 구축하는 방법에 대한 표준화된 인터페이스를 제공함. 이 표준화가 채택되어 더 쉬운 상호 운용성을 제공하기를 기대함.
- 커뮤니티 피드백:
- 제안서에 대한 피드백과 개선 방법을 환영함.
- Llama 주변 생태계를 성장시키고 개발자와 플랫폼 제공자의 장벽을 낮추는 데 흥미를 느끼고 있음.
개방성이 주도하는 혁신
- Llama 모델 가중치는 다운로드 가능하며, 개발자는 이를 완전히 맞춤화하여 새로운 데이터셋에 대해 훈련하고 추가 미세 조정을 수행할 수 있음.
- 이를 통해 더 넓은 개발자 커뮤니티와 세계가 생성 AI의 힘을 완전히 실현할 수 있음. 개발자는 Meta와 데이터를 공유하지 않고도 자체 애플리케이션에 맞춰 모델을 완전히 맞춤화하고 모든 환경에서 실행할 수 있음.
- 비용 효율성:
- 많은 사람들이 폐쇄 모델이 더 비용 효율적이라고 주장할 수 있지만, Artificial Analysis의 테스트에 따르면 Llama 모델은 산업에서 가장 낮은 토큰당 비용을 제공함.
- Mark Zuckerberg는 오픈 소스가 전 세계 더 많은 사람들이 AI의 혜택과 기회를 누릴 수 있도록 하고, 권력이 소수의 손에 집중되지 않으며, 기술이 사회 전반에 걸쳐 더 균등하고 안전하게 배포될 수 있도록 보장한다고 언급함. 이는 오픈 액세스 AI가 산업 표준이 되도록 하는 이유임.
- Llama 모델을 사용하여 놀라운 것들을 만든 커뮤니티 사례:
- AI 스터디 버디: WhatsApp과 Messenger에 배포된 AI 학습 도우미
- 의료 분야에 특화된 LLM: 임상 의사 결정을 돕도록 설계됨
- 브라질의 비영리 헬스케어 스타트업: 환자의 입원 정보를 조직하고 소통하는 데 도움을 주며, 데이터 보안을 유지함
- 오픈 소스의 힘으로 최신 모델로 무엇을 만들지 기대하고 있음.
Llama 3.1 405B로 개발하기
- 405B 모델 사용:
- 일반 개발자에게는 405B 모델을 사용하는 것이 도전적임. 매우 강력한 모델이지만, 상당한 연산 자원과 전문 지식이 필요함.
- 커뮤니티와 대화한 결과, 생성 AI 개발에는 단순히 모델에 프롬프트를 입력하는 것 이상이 필요함을 인식함. 모든 사람이 405B의 잠재력을 최대한 활용할 수 있도록 지원하고자 함.
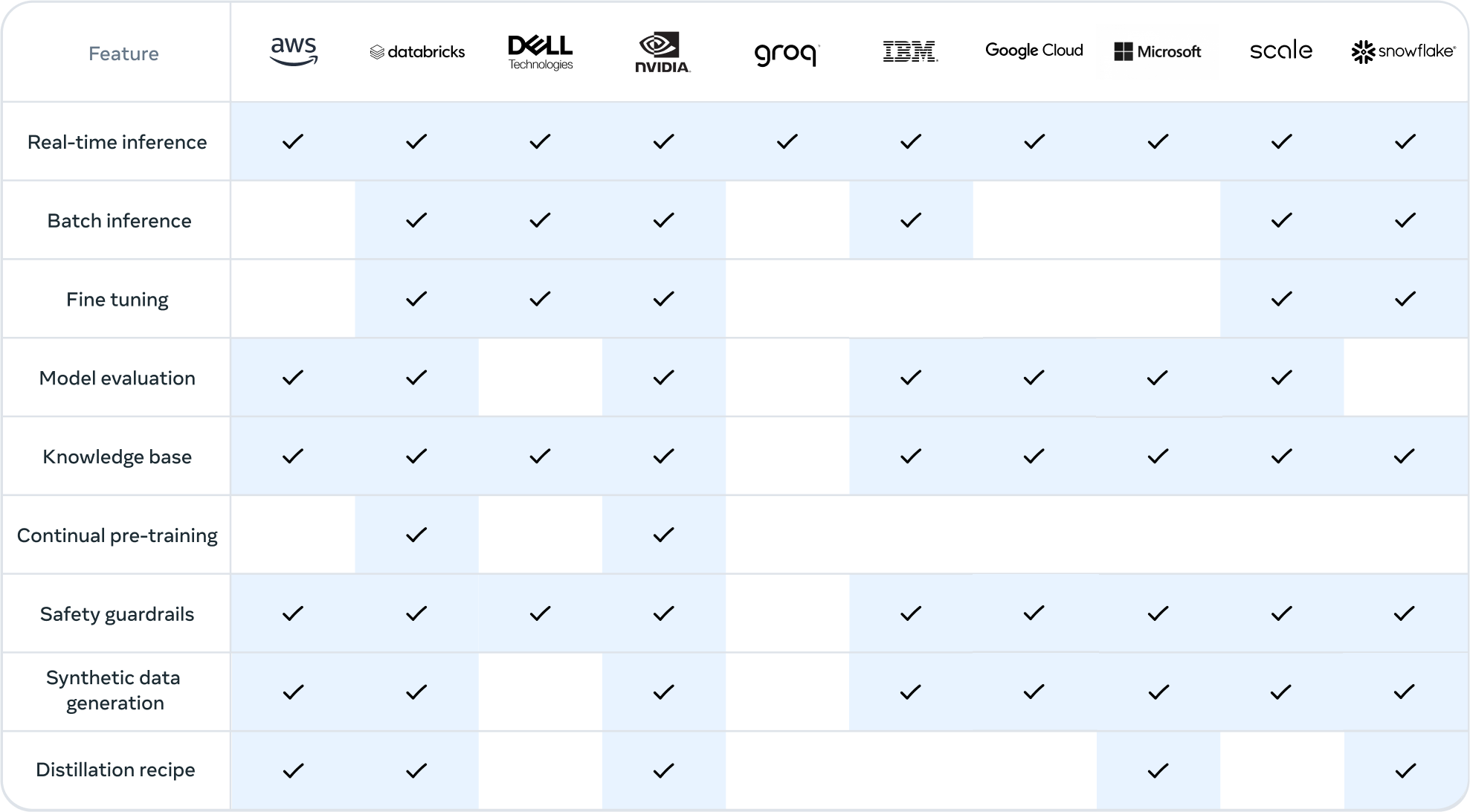
- 지원되는 기능:
- 실시간 및 배치 추론
- 감독된 미세 조정
- 특정 애플리케이션에 대한 모델 평가
- 지속적인 사전 훈련
- Retrieval-Augmented Generation (RAG)
- 함수 호출
- 합성 데이터 생성
- Llama 생태계:
- 공개 첫날부터 개발자는 405B 모델의 모든 고급 기능을 활용하고 즉시 구축을 시작할 수 있음.
- 쉬운 합성 데이터 생성, 모델 증류를 위한 턴키 지침, 파트너(AWS, NVIDIA, Databricks)의 솔루션을 통한 원활한 RAG 등의 고급 워크플로우를 탐색 가능.
- Groq는 클라우드 배포를 위한 저지연 추론을 최적화했으며, Dell은 온프레미스 시스템에 대한 유사한 최적화를 달성함.
- vLLM, TensorRT, PyTorch와 같은 주요 커뮤니티 프로젝트와 협력하여 첫날부터 지원을 구축, 커뮤니티가 생산 배포에 준비되도록 함.
- 목표: 405B 모델의 출시가 더 넓은 커뮤니티에서 추론과 미세 조정을 쉽게 만들고, 모델 증류 연구의 다음 물결을 가능하게 하기를 희망함.
오늘, Llama 3.1 모델 컬렉션을 사용해 보세요
- 커뮤니티가 이 모델로 무엇을 만들지 기대하고 있음. 다국어 지원과 확장된 컨텍스트 길이를 활용하여 유용한 새로운 경험을 구축할 잠재력이 큼.
- Llama Stack과 새로운 안전 도구를 통해 오픈 소스 커뮤니티와 함께 책임감 있게 계속 구축해 나갈 것임.
- 안전성 조치:
- 모델을 출시하기 전에 여러 조치를 통해 잠재적 위험을 식별, 평가, 완화함.
- 배포 전 위험 발견 연습(레드 팀 활동) 및 안전 미세 조정을 포함함.
- 외부 및 내부 전문가와 광범위한 레드 팀 활동을 수행하여 모델을 스트레스 테스트하고 예상치 못한 사용 방법을 찾음.
- 미래 가능성:
- 가장 큰 모델이지만, 앞으로도 더 많은 기회를 탐구할 예정임.
- 이는 더 친환경적인 디바이스 사이즈, 추가적인 모달리티, 에이전트 플랫폼 층에 대한 더 많은 투자를 포함함.
- 커뮤니티가 이 모델들로 놀라운 제품과 경험을 만들어 나가기를 기대하고 있음.
'🟣 AI Study' 카테고리의 다른 글
| Google DeepMind, AI로 국제 수학 올림피아드(IMO) 은메달 수준 달성 (0) | 2024.07.26 |
|---|---|
| Mistral, 새로운 플래그십 모델 Mistral Large 2 출시 (0) | 2024.07.25 |
| 마구잡이 질문에도 강건한 RAG 시스템 만들기: Query Transformation (0) | 2024.07.20 |
| 문서 내 이미지를 함께 활용할 수 있는 멀티모달(Multi-modal) RAG 시스템 만들어보기 (0) | 2024.06.20 |
| 검색증강생성(RAG) - LangChain과 PGVector를 이용한 간단한 RAG 시스템 구축해보기 (0) | 2024.05.13 |




댓글