
TL;DR
최근 양자화(Quantization) 등의 방법으로 LLM 경량화가 이루어지면서,
일반 사용자들이 LLM을 이용한 서비스를 구축하기가 한결 수월해졌다.
이 포스트에서는 양자화한 7B 수준의 LLM을 기반으로, 자연어 질의를 SQL로 변환해주는 생성기를 만들어 본다.
본 튜토리얼은 Colab Pro(또는 Pro Plus)의 T4 GPU 및 고용량 RAM 환경에서 수행되었다.
구글 Colab(이하 코랩)은 기본적으로 임시 디렉토리에 파일을 저장하므로, 만약 작업 중 파일을 저장하거나 불러올 때는 구글 드라이브 경로를 지정해주어야 합니다.
드라이브 마운트 후 cd 명령어를 이용해 경로를 설정해줍니다. 필요한 경우에만 실행하면 됩니다.
from google.colab import drive
drive.mount('/content/drive')%cd /content/drive/MyDrive/"folder_name"
경량화 LLM을 이용하는 방법은 다양한데, 본 포스트에서는 그 중 ctransformers라는 라이브러리를 이용해 양자화된 LLM을 불러올 것입니다.
ctransformers는 Huggingface의 transformers 패키지와 거의 유사한 형태로 LLM을 사용할 수 있어 편리합니다.
!pip install ctransformers
!pip install gradio
ctransformers를 이용해 LLM을 모델을 불러올 때, cuda 버전 오류가 생기는 경우가 있습니다.
이 경우가 아니라도 코랩은 torch나 cuda 버전 오류가 빈번하므로, 상황에 맞추어 구글링을 통해 해결해보도록 합시다.
저의 경우는 다음과 같은 명령어로 cuda를 별도로 설치해주었더니 정상 작동되었습니다.
!wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-ubuntu2204.pin
!sudo mv cuda-ubuntu2204.pin /etc/apt/preferences.d/cuda-repository-pin-600
!wget https://developer.download.nvidia.com/compute/cuda/12.3.1/local_installers/cuda-repo-ubuntu2204-12-3-local_12.3.1-545.23.08-1_amd64.deb
!sudo dpkg -i cuda-repo-ubuntu2204-12-3-local_12.3.1-545.23.08-1_amd64.deb
!sudo cp /var/cuda-repo-ubuntu2204-12-3-local/cuda-*-keyring.gpg /usr/share/keyrings/
!sudo apt-get update
!sudo apt-get -y install cuda-toolkit-12-3;
ctransformers와 gradio는 코랩에 기본 설치되어 있지 않으므로, 설치해줍니다.
Gradio는 파이썬 환경에서 간단하게 모델을 웹에 배포할 수 있는 도구입니다. Gradio는 Huggingface가 운영하는 서비스이기도 하여, Huggingface 프레임워크와 호환성이 좋습니다.
!pip install ctransformers
!pip install gradio
이제 필요한 라이브러리들을 불러옵니다.
import torch
from ctransformers import AutoModelForCausalLM
from transformers import AutoTokenizer
from transformers import pipeline
import gradio as gr
AutoModelForCausalLM와 AutoTokenizer 모듈에서 사용할 언어 모델과 토크나이저를 불러옵니다.
모델은 보통 Open LLM 리더보드에서 성능과 사이즈를 참고하여 선택할 수 있습니다.
그리고 선택한 모델의 경량화 모델(보통 기존 모델명 뒤에 GPTG, GGUF, AWQ 등이 붙어 있는 모델)의 저장소를 찾아, 해당 저장소의 모델을 불러오면 됩니다. 보통 해당 저장소의 설명 란에 ctransformers를 이용해 불러오는 형태가 명시되어 있습니다.
토크나이저는 경량화 모델의 저장소가 아닌, 기존 모델의 저장소로부터 불러옵니다.
본 포스트에서는 Intel이 Mistral의 모델을 파인튜닝하여 만든 neural-chat-7B 모델을 사용합니다.
model = AutoModelForCausalLM.from_pretrained("TheBloke/neural-chat-7B-v3-3-GGUF", model_file="neural-chat-7b-v3-3.Q5_K_M.gguf", model_type="mistral", gpu_layers=100, hf=True)
tokenizer = AutoTokenizer.from_pretrained("Intel/neural-chat-7b-v3-3")
Pipeline 라이브러리를 이용해 생성 프로세스를 구축합니다. Pipeline의 옵션은 상황에 맞게 유연하게 설정할 수 있습니다.
pipe = pipeline("text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.bfloat16,
device_map="auto")
이제 언어 모델에 프롬프트를 설정해줍니다. 우리는 사용자의 질문에 맞는 SQL을 생성하라고 지시를 할 것입니다. 추가로, SQL 생성과 무관한 질문에는 다시 사용자에게 질문을 요구하도록 설정합시다.
system = "Generate a SQL query or provide proper information to answer the following question based on database schema: "
warn = " If the user's question is not related to SQL generation, tell them to submit a SQL-related question. "
우리가 설정한 프롬프트를 사용자의 입력 및 대화 기록(history)와 적절히 결합하여 모델에 입력되도록 하는 함수를 설정합니다. 프롬프트 입력 형태는 모델마다 다른데, 각 언어 모델의 저장소를 참고하여 설정합니다.
neural-chat-7b 모델의 프롬프트 형식은 다음과 같이 주어져 있으므로, 이에 맞게 프롬프트 입력 함수를 설정했습니다.

def format_message(message: str, history: list, memory_limit: int=3) -> str:
if len(history) > memory_limit:
history = history[-memory_limit:]
global completed_prompt
completed_prompt = "### System: " + f"{system}" + f" {warn}"
for i, [user_msg, model_answer] in enumerate(history):
completed_prompt += f"### User: {user_msg} ### Assistant: {model_answer}"
completed_prompt += " ### User: " + f"{message}"
return completed_prompt
이제 답변을 생성하는 함수를 설정합니다. 참고로, 위의 format_message 함수와 아래의 get_response 함수는 Gradio 프레임워크에 호환되도록 설정한 함수입니다.
Gradio가 아닌 다른 챗봇 인터페이스도 유사한 프로세스로 구축되므로 이러한 단계를 기억해놓으면 좋습니다.
get_response 함수는 전 단계에서 설정한 pipeline 함수에 프롬프트를 입력하고, 생성된 답변을 출력합니다. 생성에 대한 다양한 옵션(생성할 최대 토큰 수, top-k/p, temperature)을 설정할 수 있습니다.
보통 언어 모델은 답변을 JSON 형태로 반환하기 때문에, 여기서 답변 텍스트만 추출하는 간단한 전처리가 필요합니다.
def get_response(message: str, history: list) -> str:
query = format_message(message, history)
response = ""
sequences = pipe(
query,
max_new_tokens=400,
do_sample=True,
temperature=0.5,
top_k=25,
top_p=0.95,
use_cache=False)
generated_text = sequences[0]['generated_text']
response = generated_text[len(query):]
print("Chatbot:", response.strip())
return response.strip()
이제 Gradio를 이용해 웹페이지를 설정해봅시다.
ChatInterface 모듈에 우리가 설정한 get_response 함수를 입력하면 간단히 챗봇 인터페이스를 구축할 수 있습니다.
추가적으로 제목과 설명, 테마(Blocks 모듈)를 설정해줍니다.
# torch.cuda.empty_cache()
with gr.Blocks(theme=gr.themes.Monochrome()) as demo:
with gr.Row():
gr.Markdown("# 🐘 SQL Generator")
with gr.Row():
gr.Markdown("""- 자연어 질의를 SQL로 변환할 수 있습니다.
""")
with gr.Row():
chat = gr.ChatInterface(get_response,
retry_btn='Retry',
undo_btn='Undo',
clear_btn='Clear ',
submit_btn='Submit ')
demo.launch(share=True)
# demo.launch()
셀을 실행시키면 Output 창에도 챗봇 인터페이스가 출력되며, share 옵션을 설정했으므로 외부에서도 접속 가능한 링크가 함께 출력됩니다.
자연어로 질문을 했을 때, 이를 SQL 잘 생성해주는 것을 확인할 수 있습니다.
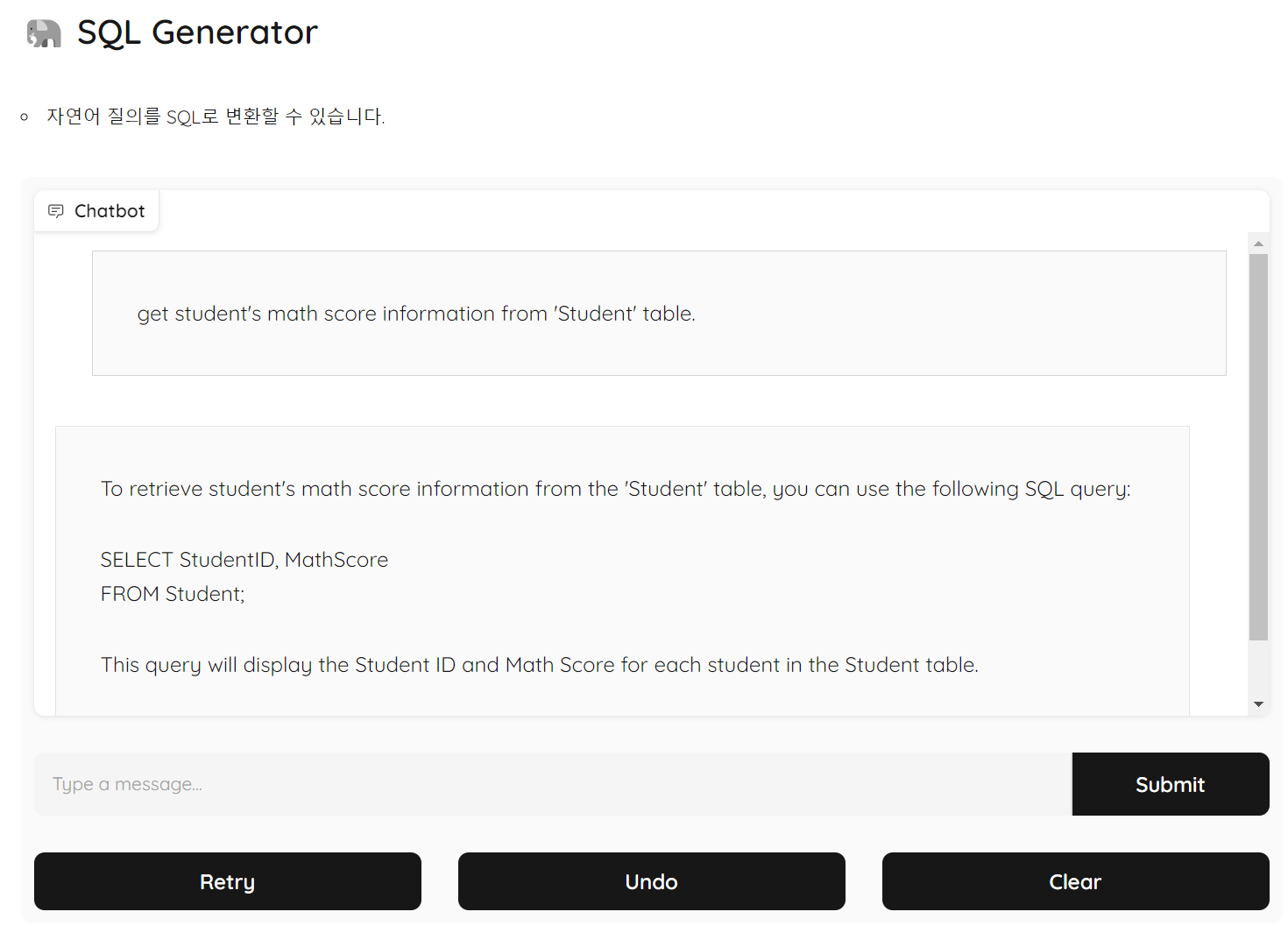
멀게만 느껴졌던 LLM을 비교적 저렴한 비용으로 이용할 수 있는 코랩에서 구축해 서비스까지 생성해보았습니다.
Production 단계까지 가려면 고려할 부분이 더 많지만, 상용화된 LLM 서비스들도 기본적으로 유사한 프로세스를 가지므로 이를 바탕으로 각자에게 맞는 LLM 서비스를 구축해보자.
'🟣 AI Study' 카테고리의 다른 글
| LLM 이해하기 - LLM의 기초 개념 (3) | 2024.01.14 |
|---|---|
| Microsoft, 2.7B의 경량 규모 언어 모델 출시: Phi-2 (2) | 2024.01.10 |
| 애플, 거대 멀티모달 모델(Large Multi-modal Model, LMM) 'Ferret' 공개 (0) | 2023.12.27 |
| Objective Function 이해하기 - 01. Probability와 Likelihood의 차이 (0) | 2023.12.19 |
| 검색증강생성(RAG): 벡터 DB 기초 (1) | 2023.11.01 |



댓글